来源:成都大数据培训机构
时间: 2018/3/16 10:47:19
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据地位。
Spark的这种学术基因,使得它从一开始就在大数据领域建立了一定优势。无论是性能,还是方案的统一性,对比传统的Hadoop,优势都非常明显。Spark提供的基于RDD的一体化解决方案,将MapReduce、Streaming、SQL、Machine Learning、Graph Processing等模型统一到一个平台下,并以一致的API公开,并提供相同的部署方案,使得Spark的工程应用领域变得更加广泛。本文主要分以下章节:
一、Spark专业术语定义
二、Spark运行基本流程
三、Spark运行架构特点
四、Spark核心原理透视
一、Spark专业术语定义
1、Application:Spark应用程序
指的是用户编写的Spark应用程序,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
Spark应用程序,由一个或多个作业JOB组成,如下图所示:

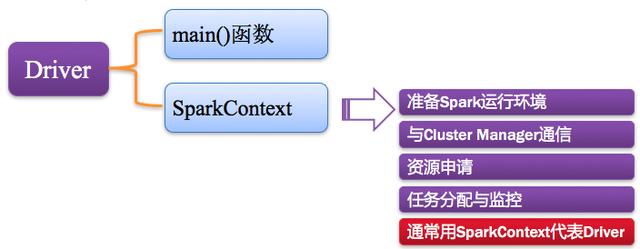
2、Driver:驱动程序
Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常SparkContext代表Driver,如下图所示:
3、Cluster Manager:资源管理器
指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Haddop Yarn,由Yarn中的ResearchManager负责资源的分配;Messos,由Messos中的Messos Master负责资源管理,如下图所示:

4、Executor:执行器
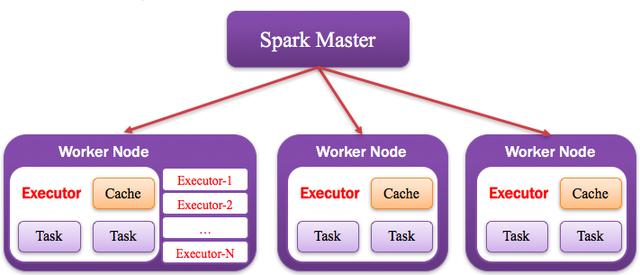
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor,如下图所示:

5、Worker:计算节点
集群中任何可以运行Application代码的节点,类似于Yarn中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点,在Spark on Messos模式中指的就是Messos Slave节点,如下图所示: